
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- uuid-ossp
- 엣지컴퓨팅
- 자료구조
- GraphQL
- 어셈블리어
- 텍스트북
- adminbro
- 파이썬
- mistel키보드
- schema first
- raycasting
- Cloud Spanner
- 레이캐스팅
- 정렬
- 쿠버네티스
- 도커
- 어셈블리
- 42서울
- SFINAE
- enable_if
- c++
- 42seoul
- 부동소수점
- psql extension
- 동료학습
- 이노베이션아카데미
- 스플릿키보드
- 프라이빗클라우드
- 창업
- 스타트업
- Today
- Total
written by yechoi
GCP - Big Data 상품(BigQuery, Cloud Dataproc, Cloud Dataflow 등) 본문
GCP - Big Data 상품(BigQuery, Cloud Dataproc, Cloud Dataflow 등)
yechoi 2021. 3. 14. 22:43GCP Fundamentals: Core Infrastrucure
Introduction to Big Data and Machine Learning
Google Cloud Big Data Platform
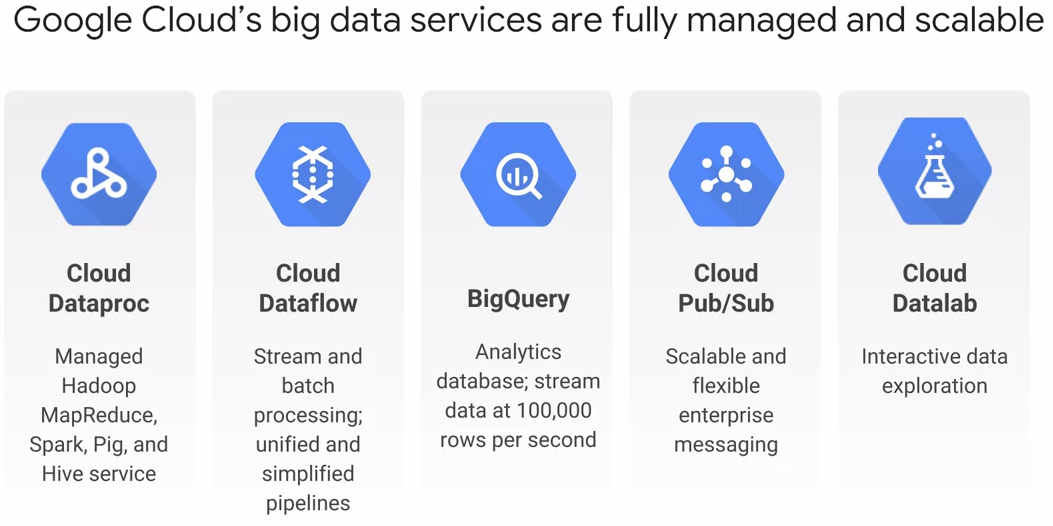
Cloud Dataproc
-
managed Hadoop MapReduce, Spark, Pig, Hive service(빅데이터 프레임워크들)
🔗 각 프레임 워크의 차이를 알고 싶다면 여기로
-
MapReduce 모델
대용량 데이터 처리를 위한 '분산 프로그래밍' 모델로 구글이 2004년 발표한 소프트웨어 프레임 워크다.
맵과 리듀스 두가지 닩계로 이뤄진다. 맵은 데이터를 키와 밸류로 변환하고, 리듀스는 중복 데이터를 제거하고 원하는 데이터를 추출하는 과정이다.
-
사용하기 위해선 Hadoop 클러스터를 요청, 가상머신 설정을 완료해야
-
스케일 업, 다운 가능하며 stackdriver로 모니터링 가능
-
하드웨어 리소스에 대한 비용만 지불하며, 비용은 초 단위로 책정
-
자원을 미리 선점하는 식으로 계약하면 80%까지도 저렴
-
Spark, Spark SQL, MLib(Apache Spark 라이브러리) 사용 가능
Cloud Dataflow

-
앞션 Cloud Dataproc은 데이터 사이즈를 알고 클러스터의 사이즈를 스스로 조정하고자 할 때 효율적
-
데이터가 실시간으로 변동하고 사이즈를 예측할 수 없는 경우 Cloud Dataflow를 사용하는 것이 합리적
-
Cloud Dataproc 과 마찬가지로 extract, transform, load batch computation, continuous computation 등 다양한 데이터 프로세싱 패턴을 지원
-
data pipeline을 설치하기 위해 사용, 같은 pipeline이 batch와 streaming data에 사용
데이터 파이프라인이란 데이터를 한 장소에서 다른 장소로 차례대로 전달하는 데이터로 구성된 일련의 시스템. ETL(extracting, transforming, loading)을 포함하는 광위한 용어. 데이터 파이프라인은 모든 종류의 스키마의 데이터를 수용해야 하고, 무엇이든 간에 데이터는 청크로 들어와 병렬로 처리된다.
-
클러스터를 구성하거나 인스턴스의 사이즈를 변경할 필요가 없음
-
어떤 프로세싱 리소스든 관리할 수 있으며, 리소스 관리나 퍼포먼스 최적화 등의 업무로부터 자유로움
-
동적으로 지연 문제를 리밸런싱하며, hotkey(비균형적으로 많은 양의 청크가 한 클러스터에 맵되는 문제) 우려를 줄임
-
주로 ETL 툴로 쓰이며, IoT 분석, 헬스케어, 실시간 어플리케이션(개인화 게임 ux) 등의 분야에서 활용
Big Query
- 더 광범위하고 많은 데이터에서 SQL 신택스 사용
- Pay-as-you-go 모델
- cloud storage, cloud data store에서 데이터를 로드하거나 빅쿼리로 초당 100,000 줄을 스트림할 수 있음
- 테라바이트 단위의 데이터의 SQL 쿼리를 초단위로 처리 가능
- Cloud Dataflow, Hadoop, Spark 에서 데이터 읽고 쓰기 가능
- 99% SLA(Service Level Agreement, 서비스수준계약)
- 데이터 보관 리전을 지정 가능
- storage와 computation 비용이 분리돼 있어, 쿼리에 대한 비용은 사용할 때만 지불하면 됨
- 장기간(90일 이상) 데이터를 Big Query에 저장할 경우 구글은 자동으로 storage 비용을 낮춤
Cloud Pub/Sub
- 동기 이벤트를 처리할 때는 Pub/Sub 메세징 서비스가 도움됨
- 애플리케이션이 메세지를 발행하면 구독자들이 수신할 수 있음
- 메세지는 동기일 필요 없어서 디커플링 시스템에 적합
- 메세지를 저지연으로 최소한 한번 공급하도록 설계됨(아주 적은 확률로 두번 이상 메세지가 보내질 수 있음)
- 초당 100만 메세지를 동시에 보낼 수 있는 온디맨드 확장성을 제공
- Stream data를 처리한다면 Pub/Sub와 Cloud Dataflow의 합이 좋음
- GCP Compute Platform 상의 애플리케이션에서 정상적 작동
Cloud Datalab
- Python, SQL과 같은 친숙한 언어를 사용하여 대화식으로 데이터를 간편하게 탐색, 시각화, 분석, 변환할 수 있음
- Integrated, Open source built on Jupiter
- Datalab 자체는 무료이며 탐색, 분석 등의 과정에서 사용하는 GCP 서비스에 대해서 비용 지불
- BigQuery, Compute Engine, Cloud Storage와 통합돼있기 때문에 불편한 인증절차를 거칠 필요 없음
- Google charts, map plot line 등으로 데이터 시각화 가능
- 이미 통계 패키지로 발행된 노트북이 많기 때문에 활용해볼 수 있음
Google Cloud Machine Learnind Platform
Cloud Machine Learning Platform
-
미리 훈련된 모델을 통해 머신 러닝 서비스를 제공
-
자신만의 모델을 만들어볼 수도 있음
-
TPU(Tensor Processing Units)를 통해 180 테라플롭(초당 부동소수점 연산)의 성능을 냄
TPU(텐서 처리 장치)는 Google에서 맞춤 개발한 ASIC(Application-Specific Integrated Circuits)로서 머신러닝 작업 부하를 빠르게 처리하는 데 사용됩니다. TPU는 Google이 머신러닝 분야에서 쌓은 심화된 경험과 경쟁력을 바탕으로 설계되었습니다.
Cloud TPU 리소스는 머신러닝 애플리케이션에서 주로 사용되는 선형대수 연산 성능을 가속화합니다. TPU를 사용하면 복잡한 대형 신경망 모델을 학습시킬 때 정확성 달성 시간을 최소화할 수 있습니다. 다른 하드웨어 플랫폼에서는 학습하는 데 몇 주가 걸렸던 모델이 TPU에서는 몇 시간이면 수렴 단계에 도달할 수 있습니다.
-
Google Cloud Machine Learning Engine: 대규모의 managed clustured에서 어떠한 종류의 데이타든 텐서플로 모델로 처리할 수 있음
Machine learning APIs
- Cloud Vision API: 이미지의 내용을 빠르게 categorize할 수 있음
- Cloud Speech API: 음성을 텍스트로 변환가능, 80개 이상의 언어 지원
- Cloud Natural Language API: 자연어 분석, 문장의 감정 분석 (영, 서, 일어)
- Cloud Translation API: 임의의 언어를 지원하는 언어로 변환
- Cloud Video Intelligence API: 비디오에 주석을 달 수 있음 (검색기능과 연관 등 가능)


